
The Struggle: Transcribe stuff for free with Whisper and WSL/Linux – With a GTX 1060
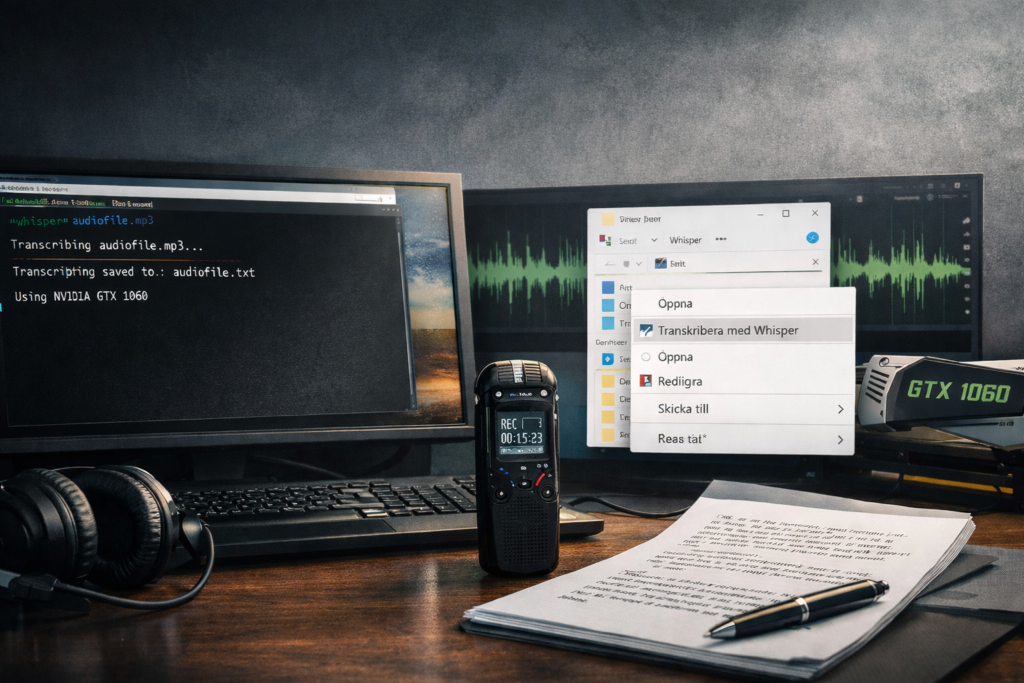
I’ve been struggling with transcription issues for quite some time, for a variety of reasons. Examples: I need a text transcribed to be pasted into Suno, that only exists as a m4a-file (i.e. music, that sometimes has hardcoded subtitles that has to be manually transcribed). Etc.
I first found a Samsung app that could handle transcription, but it quickly became clear that it was limited to its own ecosystem. In practice, you could only transcribe audio that had been recorded inside that specific app.
Since then, I’ve been looking around on and off, and more recently I picked it up again as the need increased – partly to get correct transcriptions, but also to be able to process any audio files I download or record. Samsung’s app is decent, but the quality varies. Right after recording, it performs a quick transcription, but the result is noticeably worse than if you re-run the transcription once the audio file is fully finalized.
At that point I came across “Whisper Transcribe” for Windows. It works, but it requires an account and, of course, paid credits to continue transcribing. You get a small number of free credits at first, but once those run out, you’re expected to pay quite a bit just to keep going.
I already knew that there must be software capable of doing this completely locally. I had previously discovered that Whisper exists in an open-source form as well (I’m not even sure whether the Windows application actually builds on that or not). So today I decided to finally figure out how to do it properly myself.
The end result was the following (thanks to ChatGPT):
- A Whisper installer for WSL/Linux, with explicit support for NVIDIA GTX 1060 – something newer Python libraries clearly no longer handle well.
- A Whisper runner for WSL/Linux: run
whisper <input-file>and get a.txttranscript generated from the audio file. - A Windows Registry file that allows transcription to be executed directly from Windows Explorer via right-click.
- A batch file that bridges Windows and WSL so everything runs cleanly, including proper handling of spaces and non-ASCII characters in file names.
The result is a fully local, offline transcription setup that works on any audio file, without accounts, credits, or vendor lock-in.
WSL uses python and pip…
whisper.bat
@echo off
setlocal EnableExtensions
REM Force UTF-8 codepage (fixes å ä ö)
chcp 65001 >nul
REM File passed from Explorer
set "WIN_FILE=%~1"
REM Convert Windows path to WSL path (UTF-8 safe now)
for /f "delims=" %%i in ('wsl wslpath "%WIN_FILE%"') do set "WSL_FILE=%%i"
REM Run whisper on that file
wsl bash -lc "/usr/local/tornevall/whisper \"%WSL_FILE%\""
endlocalwhisper.reg (explorer right clicks)
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\*\shell\WhisperWSL]
@="Transkribera med Whisper (WSL)"
"Icon"="wsl.exe"
[HKEY_CLASSES_ROOT\*\shell\WhisperWSL\command]
@="\"F:\\viktigt\\Private\\Linux-Scripts\\Whisper.bat\" \"%1\""installer för WSL/Linux (with 1060-compatibilty and pre-uninstaller)
To make sure stuff are removed properly before reinstalling there is a -u switch for this in the script. In case you make it wrong the first time, this switch is there to make sure you can reinstall it a second time without conflicts.
#!/usr/bin/env bash
set -euo pipefail
VENV_DIR="${VENV_DIR:-$HOME/.venvs/whisper}"
MODE="install"
# --- Parse args ---
while getopts ":u" opt; do
case "$opt" in
u) MODE="uninstall" ;;
*)
echo "Usage: $0 [-u]"
exit 1
;;
esac
done
echo "==> Whisper installer (GTX 1060 compatible)"
echo "==> Mode: $MODE"
# --- Sanity ---
if [[ ! -d "$VENV_DIR" ]]; then
echo "Error: venv not found: $VENV_DIR"
exit 1
fi
# shellcheck disable=SC1090
source "$VENV_DIR/bin/activate"
python -m pip install --upgrade pip setuptools wheel
# ==================================================
# UNINSTALL MODE (-u)
# ==================================================
if [[ "$MODE" == "uninstall" ]]; then
echo "==> Uninstalling incompatible packages ONLY (-u)"
pip uninstall -y torch torchvision torchaudio || true
pip uninstall -y numpy || true
echo ""
echo "Done."
echo "Uninstall completed. Nothing else touched."
exit 0
fi
# ==================================================
# INSTALL MODE (DEFAULT)
# ==================================================
echo "==> Installing compatible stack (no forced uninstall)"
pip install \
numpy==1.26.4 \
torch==1.13.1+cu116 \
torchvision==0.14.1+cu116 \
torchaudio==0.13.1 \
--extra-index-url https://download.pytorch.org/whl/cu116
# --- Verify ---
echo "==> Verifying environment"
python - << 'EOF'
import torch, numpy
print("Torch:", torch.__version__)
print("NumPy:", numpy.__version__)
print("CUDA available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU:", torch.cuda.get_device_name(0))
print("Capability:", torch.cuda.get_device_capability(0))
EOF
echo ""
echo "Done."
echo "Install completed without destructive actions."The script itself
The script can run without any switches – and only with the audio file intended to be transcribed (but as you can see, it can do a bit more).
#!/usr/bin/env bash
set -euo pipefail
# whisper-run.sh
# Usage:
# whisper <input.extension> [model] [language]
#
# Output:
# <input-filename>.txt (same directory)
#
# Behaviour:
# - Refuses to overwrite existing .txt
# - Stops execution if output exists
if [[ $# -lt 1 ]]; then
echo "Usage: whisper <input.extension> [model] [language]"
exit 1
fi
INPUT="$1"
MODEL="${2:-small}"
LANGUAGE="${3:-}"
if [[ ! -f "$INPUT" ]]; then
echo "Error: Input file not found: $INPUT"
exit 1
fi
BASENAME="$(basename "$INPUT")"
STEM="${BASENAME%.*}"
OUTDIR="$(dirname "$INPUT")"
OUTPUT="$OUTDIR/$STEM.txt"
# --- Refuse overwrite ---
if [[ -f "$OUTPUT" ]]; then
echo "Error: Output file already exists:"
echo " $OUTPUT"
echo "Aborting to avoid overwrite."
exit 1
fi
# Prefer venv whisper if installed via install script
WHISPER_VENV="${WHISPER_VENV:-$HOME/.venvs/whisper}"
WHISPER_BIN="whisper"
if [[ -x "$WHISPER_VENV/bin/whisper" ]]; then
WHISPER_BIN="$WHISPER_VENV/bin/whisper"
fi
if [[ "$WHISPER_BIN" == "whisper" ]] && ! command -v whisper >/dev/null 2>&1; then
echo "Error: whisper not found in PATH or venv."
exit 1
fi
TMPDIR="$(mktemp -d)"
cleanup() { rm -rf "$TMPDIR"; }
trap cleanup EXIT
echo "==> Transcribing:"
echo " input: $INPUT"
echo " output: $OUTPUT"
echo " model: $MODEL"
echo " lang: ${LANGUAGE:-auto}"
ARGS=(
"$INPUT"
--model "$MODEL"
--output_dir "$TMPDIR"
--output_format txt
--task transcribe
--verbose False
--fp16 False
)
if [[ -n "$LANGUAGE" ]]; then
ARGS+=( --language "$LANGUAGE" )
fi
"$WHISPER_BIN" "${ARGS[@]}"
GENERATED_TXT="$TMPDIR/$STEM.txt"
if [[ ! -f "$GENERATED_TXT" ]]; then
FOUND_TXT="$(find "$TMPDIR" -maxdepth 1 -type f -name "*.txt" | head -n 1 || true)"
if [[ -z "${FOUND_TXT:-}" ]]; then
echo "Error: No .txt output produced."
exit 1
fi
GENERATED_TXT="$FOUND_TXT"
fi
# --- Final move (no overwrite possible due to earlier check) ---
mv "$GENERATED_TXT" "$OUTPUT"
echo "==> Done:"
echo " $OUTPUT"Discover more from Tornevalls
Subscribe to get the latest posts sent to your email.